NEUSREL is the ultimate way to discover success drivers and is far more then a conventional Key Driver Analysis. This self-learning causal analysis is not just a more valid but also more practical procedure to key driver analysis.
What can marketing mix modeling do? What can’t it do, and what should you pay attention to when choosing methods and providers? We’ll go through the five most important questions that you should ask.
Marketing mix modeling arose from the realization that the simultaneous effects of individual marketing measures can’t be determined through descriptive data evaluation. Correlation coefficients or key indicator comparisons, “with vs. without measure X,” are inherently biased – this is the classic spurious correlation effect.
The regression analysis approach can help to determine which measures have which effect. In principle, they can do that. The effectiveness of the results is based on what the data set looks like and which methods of analysis you use. You should pose the following 5 questions before starting.
Can your Marketing Mix Modeling algorithm detect non-linear relationships and interactions between marketing channels?
Every marketing channel becomes saturated at some point. Further investment will not bear the same dividends as the initial investment. It is even often the case that after a certain point, additional expenditures can even have negative effects. This phenomenon is called non-linearities.
Furthermore, among media experts, it is almost general knowledge that marketing channels together have more of an effect than the sum of the individual effects. This phenomenon, which is used in management synergy, is called, “interactions” in statistical language. So, it’s surprising that most marketing mix models manage to get along completely without modeling these interactions.
Can your Marketing Mix Modeling algorithm find what is unknown up to this point?
In principle, with the help of econometric models, it has been possible to model non-linearity and interactions for a long time. The requirement is, however, that you have to know beforehand which non-linearities and interactions appear where. Then, the methods can determine its parameters.
Marketing mix models can have 100 variables. This means 10,000 possible interactions. On top of that, there are different kinds of interactions (AND, OR, XOR, etc.). That makes this especially time-consuming.
Furthermore, practical experience shows that the existing knowledge available is virtually never enough to stipulate the exact parameters for the econometric models.
That is precisely the large, practical advantage and the purpose of Universal Structural Modelling and NEUSREL. It doesn’t need any prior knowledge; it finds every arbitrary non-linearity and interaction independently. The result is a significantly higher explanation-power.
Do the Marketing Mix Modeling methods take indirect effects into account?
Regression and econometric models depict the relationship between driver variables and result variables. They measure direct effects exclusively, under the assumption that the drivers don’t mutually influence each other. An assumption which, in a digital age with many interactive touch points, can no longer be maintained.
In a marketing mix project for a mobile telecommunications provider, the Universal Structural Model and NEUSREL made it clear that after the television advertisement, people began to google the offer. This, in turn, led to significantly more Google AdWord clicks which, in turn, led to product sales.
TV is the driving cause. However, TV only had a very small direct effect on product sales. And this is only proven by regression analyses. Without taking the indirect effects into consideration, a very unrealistic view on TV’s effectiveness would arise.
Does your data set make the evaluation of long-term effects possible?
Marketing mix models count as methods that only measure short-term effects. The situation isn’t a question of analysis methods, but rather a question of the data used. Also, two steps also lead to making long-term effects measurable.
First, longer-term effects can be considered by using multiple target variables that differ on the time horizon. So, not only the sales numbers of the next weeks are used, but rather also those in 2 weeks, one month or even in 6 months.
Secondly, market research-based variables such as brand preference can be included as intermediate sizes in the model. These steps allow you to measure which influence marketing channels have on brand preference. Also, they allow you to measure which influence the changes in brand preference have on sales numbers. The key feature is that the increase of the brand strength is a short-term, intermediate effect. But it also has a long-term impact because it is proven that brand attitudes are long-term values. With this background knowledge, the long-term effects are realized over a horizon of 1 to 2 years.
Does the Marketing Mix Modeling method make the simultaneous visualization of all relevant channels possible in a given number of cases?
Marketing mix modeling was simpler a few years ago. There were TV, radio, print, and billboards. Today there is AdWords, thousands of types of online banners, online affiliate ads, pre-rolls, and so on. (More examples: game commercials, press releases, inbound telephone contacts, shop visits, video-based outdoor formats, website traffic, social media engagement, mobile ads, company events, sponsoring, product launch specials, competitions spendings, etc. etc. etc.)
When we assume that these dozens of channels influence each other in their effects and build synergies, it will make sense to integrate them all into one model.
The problem:
The more variables are incorporated into a model; the more data points are necessary to validly specify the model. At best, however, data are mostly used every week, which leads to data sets that have merely 50 to 100 data points. In this number of cases, regression approaches can only tabulate 5-10 variables sensibly – if you want to receive robust results.
We have implemented a technology in NEUSREL that has already been used very successfully in genetics, among other fields. Here, data sets are processed that have significantly more variables (=chromosomes) than data sets (=test subjects). This is possible thanks to a methodology trick. The method doesn’t try to explain an outcome variable anymore, but rather many target variables simultaneously.
Sales numbers in various sales channels are an example. All these outcome variables have common drivers and causes. The method compresses the driver variables into a few proxies (so-called components). The known Principle Components Analysis or Factor Analysis work differently. They create proxies that are in the position to account for the driver variables as far as possible. The new method creates the proxies in such a way that these can then optimally forecast the target variables. This is a fundamental and decisive difference.
The importance of the method is enormous. In the usual case numbers, it finally incorporates all of the relevant, influential factors. And this is precisely what delivers significantly more representative models. Additionally, there is a need to incorporate ever shorter timeframes into the analysis, especially when campaigns only run for a limited period.
Summarized …
the answer to these five questions gives the answer to which method should be used:
Can the method of analysis depict non-linear relationships and interactions between marketing channels?
Can the analysis methods of such non-linearities and interactions find what is unknown up to this point?
Do the analysis methods take indirect effects into account?
Does your data set make the evaluation of long-term effects possible?
Does the analysis method make possible the simultaneous visualization of all relevant channels in a few cases?
At the moment, there is only one methodology and one software that lives up to all the demands. It is the Universal Structure Modelling that is implemented in NEUSREL software.
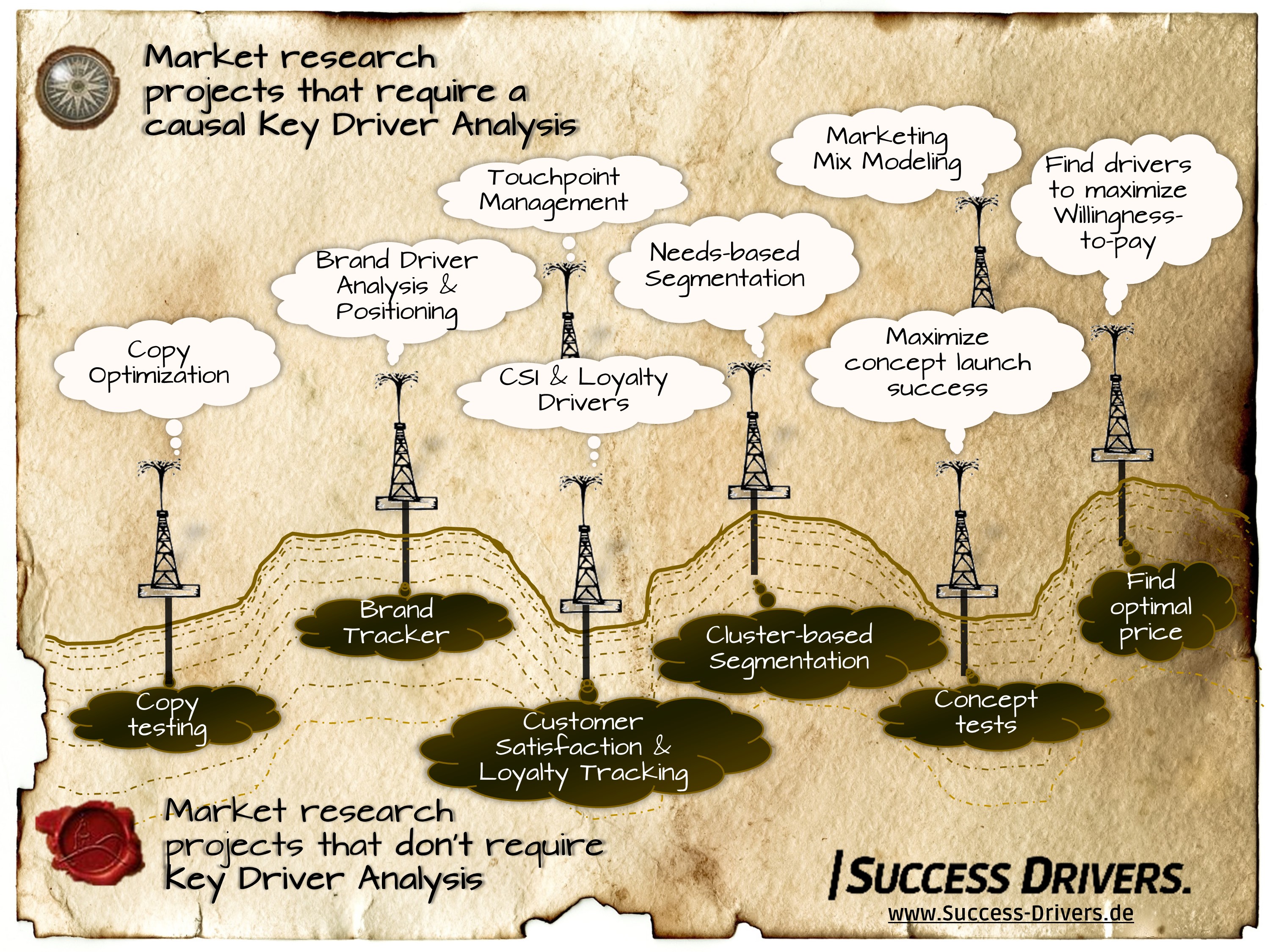
Today, driver analyses are only used in a few application areas; however, they possess a much broader application potential.Let us shed light on where their use makes sense.
At the beginning, you should write down what your research goals are. Is your goal to gather facts or to just be able to picture the customer better? How much of the market share do we have? What does the customer think about us? How satisfied are the customers? How well will the new advertisement be remembered? In all of these cases, you don’t need a key driver analysis!
Often however, behind the search for facts, there is one fundamental question: What can I do to increase revenue, to make customers more satisfied or to make an advertisement more effective? Always then, when you would like to know which factors influence your goal, this is then no longer directly visible in the data. That is when you have to use driver analyses.
Apply driver analyses for all questions about causes and searches for most effective measures.
In a copy test, for example, you can measure the advertisement recall and ask the respondents what they thought of the ad. However, consumers are not in the position to honestly be able to explain the causes for their desires and actions, nor are they always willing to. No one will say to you, “Since the brand logo wasn’t faded in at the end, I can’t remember much about the advertisement.”
Driver analyses offer the solution. After a randomised commercial break, brand images and consumer acceptance is determined in a survey. Based on the data, the driver analysis can determine which effect an advertisement had on e.g. the brand image and consumer acceptance.
Without the right data, key driver analyses are only half as effective
With driver analyses, you learn what the advertisement triggers, changes and influences. With the right question items, precise indicators for improving the advertisement can be determined.
You are perhaps asking yourself, why e.g. respondents can’t simply just be compared: For example, the consumer acceptance of those who saw the ad vs. those who haven’t seen it. The answer is simple. They are not the same people. Both samples are always different.
The control group can include, for example, many people that already know and love the product. Their answers on consumer acceptance will turn out to be significantly different. The driver analysis tabulates all other influences (like, for example, if someone is already a customer) and can then determine the true effect.
Every second market research project should use key driver analyses
If you go through the lists of the usual market research projects, you will notice that in almost all of them, the questions “why” and “what’s to do” arise. Be it copy tests, concept tests, customer satisfaction and loyalty studies, brand tracking, positioning and segmentation studies.
A question that’s puzzling at first:Aren‘t there many ways to find insights?Yes and no.There are various steps in the process and depending on the situation in which you find yourself, different methods are advisable.
Some things in life are simple. You try them out and, with experience, you notice what works and what doesn’t. Now in marketing and sales that approach doesn’t work anymore. Too many factors drive outcomes simultaneously. On top of this, actions need some time before they bear fruits. In the end, it is no longer possible to tell which actions had which influence – just from looking at the changes in measure of success.
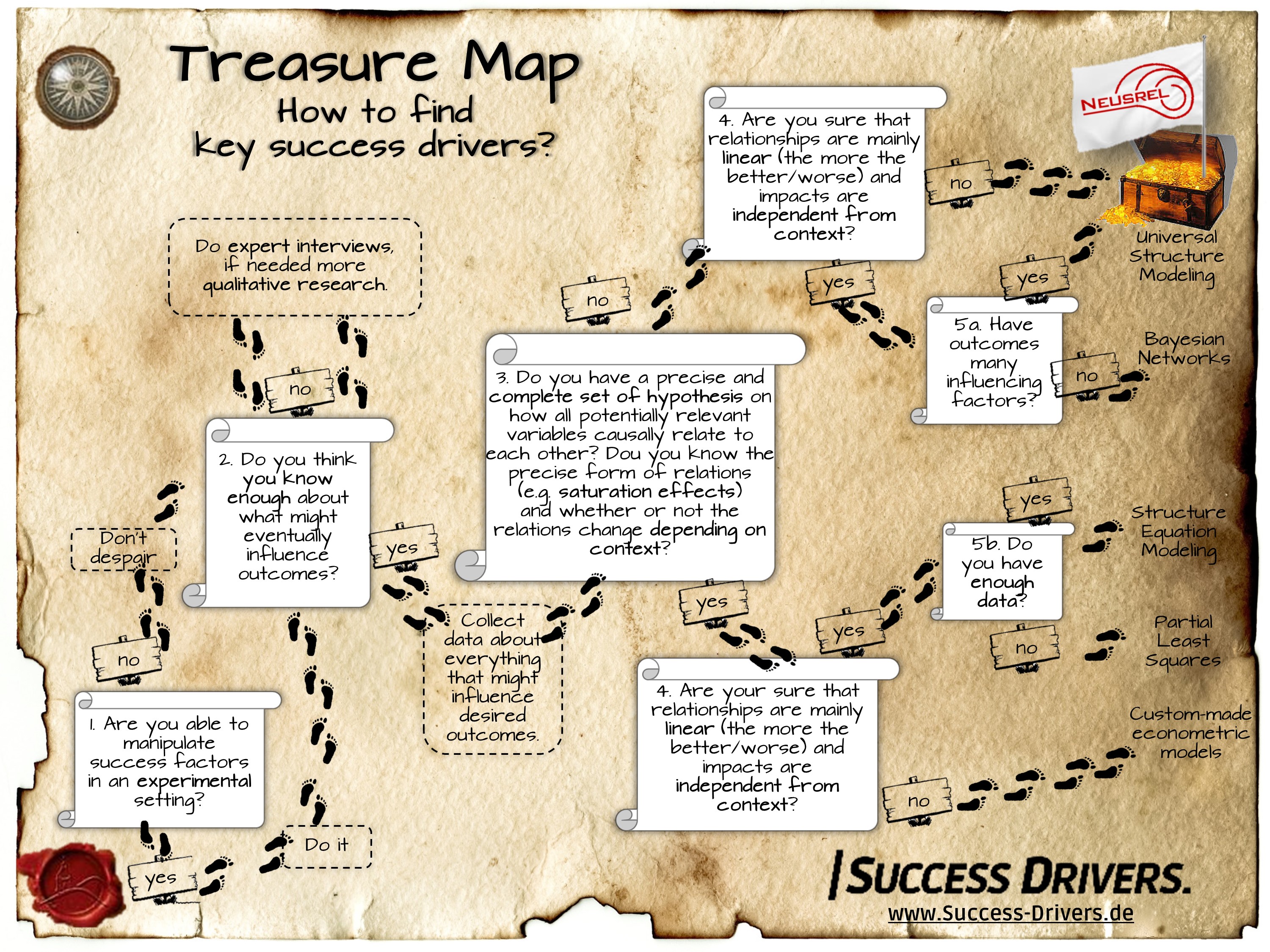
What’s to do? (1) Trial and error is still the best way to find out if something works. Only you have to track all other relevant influences in order to subsequently be able to understand the exact effect of the measures taken. Sometimes however, testing is too risky or results in immense costs.
Under the assumption that one of the ways to fine-tune success isn’t controlled by a completely different background variable, the same findings can be read from the data sets even without experimenting. This is exactly what key driver analyses do.
Qualitative research is a necessary, preliminary step for quantitative key driver analyses
(2) The danger that your results are erroneous increases when the models aren’t complete and important drivers are missing. It is especially important to take into account the drivers that influence other drivers as well as the end results. Exactly for this reason, it’s essential to have a good, qualitative preliminary phase. The subject matter and the relevant factors have to be well understood.
Only the qualitative phase isn’t enough on its own. It is not appropriate for correctly assessing the importance of a cause. Time and again in qualitative projects, researchers gain the impression that they understood exactly the key factors for success.
However, studies show that for various reasons, this is almost never the case. Still, qualitative methods are capable to discover what could be important and this is always the first key step.
The fundamental question:Do you want to test hypotheses or discover new properties and relationships?
(3) Only now does the quantitative driver analysis come into play. The choice of the right method depends on the question: how much do you already know about the relationships between the variables? Do you know the principal relationships between the aspects and would you like to measure how strongly these assumed relationships actually are? Then it’s advisable to use either econometric models or the process of structure equation modelling.
If this isn’t the case, then you need explorative methods. (4a) If you are certain that it’s enough to accept linear relationships and to assume that drivers don’t contribute to their effect, then Bayesian Networks (also called “Directed Acyclic Graphs”) are a good choice, as long as outcomes don’t have a lot of possible direct key success factors.
(5a) However, according to our experience, all of these assumptions can hardly be justified in practice. In these cases, Universal Structural Modelling offers the flexibility, free from such assumptions, to be able to map how the relationships actually play out.
The approach is implemented and available in the NEUSREL software.