BrandGrowth.AI: A proven, evidence-based strategy for more growth of your brand
In recent years neuroscience has provided the scientific proof. The result of human decisions can be detected in the brain already one to seven seconds before it has entered consciousness. Well, 90% of our decisions can be explained by unconscious emotions, attitudes, and instincts. However, most advertisements still focus on the potential product benefit and other USPs. The consequences are far-reaching.
Consumers make thousands of choices every week and are exposed to thousands of advertising contacts. It is neither practical nor relevant for people to process and understand all of them, or even to enter into a “relationship” with a relevant number of brands.
The scientific models developed by Ehrenberg and Bass decades ago are based on a different understanding of consumers – with success. They predict consumer behavior and thus the market structure very precisely. Large empirical studies have confirmed this over the last decades in hundreds of product categories across the different cultures.
Ehrenberg und Bass: A milestone in marketing research
In his book “How Brands Grow”, Byron Sharp – the current director of the Ehrenberg Bass Institute – has outlined on the basis of cross-cutting empirical studies which far-reaching consequences for convenient marketing strategies the new consumer understanding has.
He proves that placing the focus on winning new customers is more effective than binding the existing ones. Coca Cola makes more than 50% of its sales with customers who buy a coke only 2 to 3 times a year. Just about every brand makes a relevant revenue share with a large number of occasional customers – the “long tail”. This opens up an enormous growth potential.
Sharp also empirically proves that positioning on the basis of emotional differentiation is overestimated and he shows that branding is about more fundamental things. It’s about
- being saliently perceived and anchored in order to enter the choice at the moment of the decision,
- ensuring that advertising contents are placed in a context by arousing the right emotions and it is about
- maintaining continuity so that the brand image is strengthened over time rather than diluted.
As a third point, Sharp proves that it is important to keep the brand “available” in all respects in order to exploit the full potential. “Make it Easy to Buy” is the motto. This not only includes the dissemination of CPG products on the market, but also their visibility there or the avoidance of various, in hindsight partly trivial buying obstacles.
BrandGrowth.AI: Success Drivers’ solution for more growth of your brands
In the growth package “BrandGrowth.AI” we have compiled our patented analytics solution. It includes the key steps that we recommend to all brands in the market to strengthen their position in the long term and generate growth.
 1. Be Broad –Exploit as much potential as possible
1. Be Broad –Exploit as much potential as possible
Step 1 – Define your playground
Is Head & Shoulders a shampoo or a men’s anti-dandruff shampoo? The brand is bought by men and women most of whom in addition have no relevant dandruff problems. With selective targeting, the brand would not be the world’s best-selling shampoo brand. But how do you find the right scope, the appropriate definition of the “playing field”? Exactly for this, there are methods such as the intersection analysis that can help.
If you believe your brand owns a real USP, then this would be an occasion to think about expanding or changing the category understanding. Why? Rational decision-making processes are more likely to be found in the choice of product category and less in the selection of brands.
Step 2 – Find you’re optimal set of Category Entry Points
You pass McDonalds while driving and you still did not had breakfast. If the brand is not associated with breakfast, you’ll drive by without noticing you have missed an option. Did you ever ask yourself why tomato juice is mainly consumed in planes? Flying is (for whatever reason) a central Category Entry Point (CEP) for tomato juice.
Brands grow if they are associated with more relevant CEP’s. We identify qualitatively potential CEP’s, measure the relevance using implicit methods and identify how your brand is already associated with relevant CEP’s.
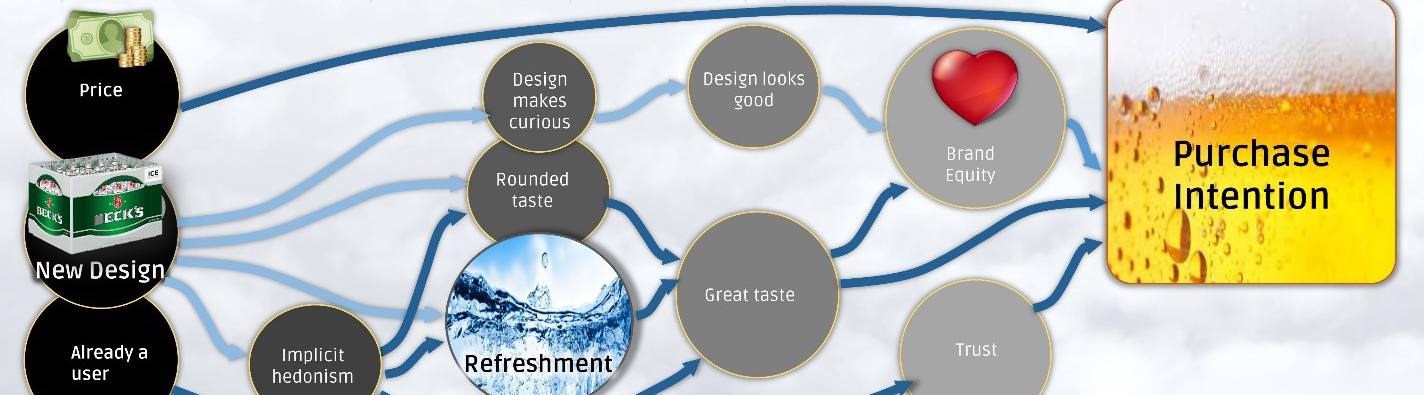
Step 3 – Category.AI – Find your category drivers
For the buyers of a category, the lowest common denominator needs to be found, which allows for convincing as many buyers as possible. Our AI-based driver analysis covers the central levers of each product category by means of simple brand surveys.
Here we find that the core driver for the beer category is the refreshing experience. We discover that in the skin cleansing category, the fragrance is the central purchasing indicator. We demonstrate that a bank should primarily focus on its expertise in financing and investment.
These core drivers are the lighthouse for your marketing. At times it seems too trivial that a beer refreshes, a shampoo smells good and a bank provides good advice. It is therefore often the rule instead of the exception that brands move too far away from this lighthouse.
This case study, using the example of the SONOS brand, illustrates the procedure.
 2. Build Brand – Maximize the “mental availability”
2. Build Brand – Maximize the “mental availability”
Branding aims to strengthen the mental availability by strengthening memory structures related to brands. This is achieved by the use of unique brand elements (logo, colors, figures, melodies, stories and associations) which are constantly used over years and decades. However, this anchoring can only be achieved if it is possible to involve advertising content emotionally – or when the brand is shown in emotionally involved contexts (keyword sponsoring).
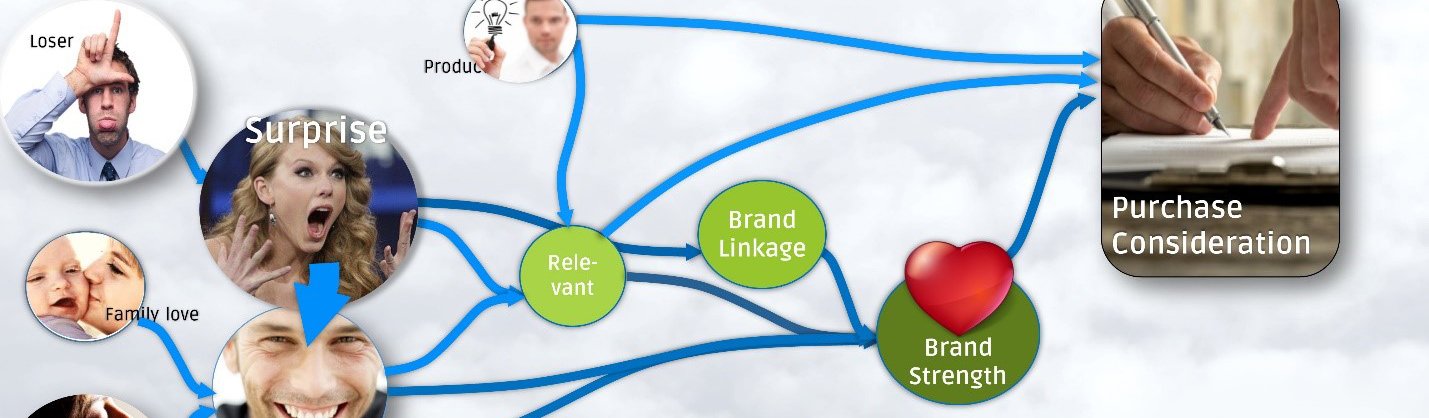
Step 4 – Creative.AI – Identify the DNA of successful advertising:
Our Creative.AI solution is designed to find out which emotional archetypes and creative techniques are capable of involving customers in a positively emotional way and thus cause a deeper anchoring of the brand elements. Find out more about Creative.AI here
Many large-scale studies show that at least 70% of the advertising effect depends on how well it is done. The evidence-based optimization of creative content is therefore of crucial importance. Only when this step has been completed does it make sense to optimize the distribution of marketing budgets more precisely:
Step 5 – Media.AI – Media planning with maximized reach
According to current state of research it is a fact that the first advertising contact has the highest ROI. Repeating contacts are only reasonable if there is no alternative target group available with similar response to the advertising. Byron Sharp showed with great empirical evidence that advertising has greatest impact at light category buyers (long tail), typically not within the “core target group”.
That’s why impactful media planning is less focused on razor-sharp targeting but maximizing reach within the group of potential category buyers. Media.AI samples individual media usage profiles among category buyers and than computes (by leveraging A.I.) those combination of media channels, types and times that maximizes reach with an existing budget.
Step 6 – Mix.AI – Mix modeling in the digital age
Marketing Mix Modeling is an established method. However, it requires an update. In the digital age, channels mutually define each other to a growing extent. A TV spot generates Adword clicks – an indirect effect that must be taken into account. AI-based driver analyzes not only depict this indirect relationship, but also find hidden synergies, i.e. interaction effects between channels. More about our MMM approach.
Step 7 – SLC-Brand Tracker: The 3 central KPIs always in focus
Brand trackers nowadays primarily measure the brand image in order to check whether the brand is still perceived according to definition. However, it is much more crucial to track how salient, “likable” and continuous the brand management is:
- Salience (brand salience): It measures how many anchor points the brand occupies to be recalled and retrieved at the required time. In order to optimally measure the brand’s salience, a separate measuring instrument must be developed that scans all brand “cues”.
- Likability: Is the brand associated with positive emotions and with the basic benefit of the category?
- Continuity: Is the brand communication based on existing memory patterns or is it diluted by building new ones?
 3. Reach out – Maximize the “physical availability”
3. Reach out – Maximize the “physical availability”
Under the concept of “physical availability”, we understand that the brand is in the perception field of the consumer when required and meets certain knock-out criteria (for example, desired package size, price category, etc.). The degree of dissemination on the market here is only one of many obvious components.
Step 8 – RNB.AI: Identify the reasons NOT to buy
Brands whose apparent success is “convenience” often have eliminated certain knock-out criteria. Shining examples are PayPal, Google Search, Nintendo Wii or the iPhone. Interestingly, to marketing experts it is by no means obvious in advance what exactly these criteria are. More detailed research is required. We recommend a two-step approach
- Qualitative research: depth interviews, focus groups or communities
- Quantitative exploration: Our AI-based driver analysis reads from a quantitative survey concluded for this purpose which criteria are actual “show-stoppers”.
The approach has been designed and tested for a current product category on the market as well as for new product concepts.
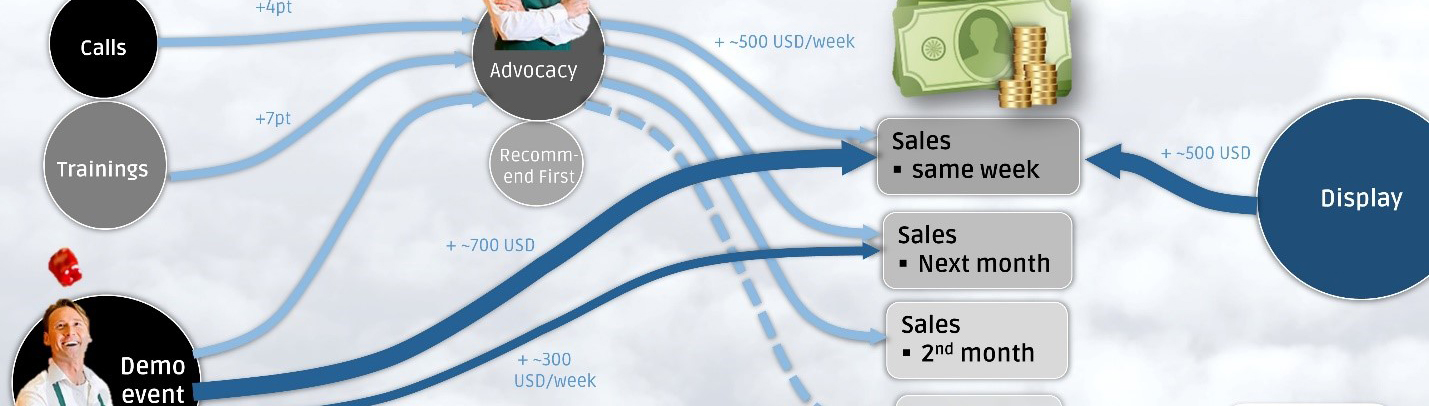
Step 9 – Sales.AI: Maximize the impact force at the POS
The impact force at the POS can be increased by a variety of measures: displays, in-store furniture, demo events, sales training, price promotions, etc. However, their effectiveness is not directly reflected in the data. Thus, some measures have long-term (training) and other short-term (price promotions) effects. Sales.AI establishes a convenient record and evaluates the ROI of these sales promotion activities.
Step 10 – Price.AI: Find price points that are acceptable to the majority and maximize long-term returns
A price point that is too low will jeopardize the long-term “survival” of a product – too high a price reduces the actual availability and prevents the full profit potential from being exhausted. The price is not only the easiest to change marketing parameter it is also known to be the most effective one. Every dollar increase is one dollar profit.
Price.AI is based on an implicit measurement of the price stability and models the causes, conditions and leverage of the willingness to pay. This makes it possible to find and manage optimal long-term price points.
The BrandGrowth.AI Audit – Find out what works for you
BrandGrowth.AI is a collection of tools that are applied at the most important parameters for brand growth. It provides focus, highest validity and transparency in the jungle of methodological possibilities.
We offer new customers a free-of-charge audit workshop in which we will discuss with you what your individuals needs are to be able to move your brand to the next level. With a little bit of luck, it will be the same as with T-Mobile USA, who, 4 years after the implementation of Category.AI., have doubled their market share and today are making record profits.